on
Scalable Machine Learning Application
Imagine having a heavy Machine Learning model you want to use in a data-intensive pipeline in your application.
To keep your whole system decoupled, you’d probably want to encapsulate the model in a microservice to satisfy the specific computational requirements easier and scale the service independently of the rest of your application.
Let’s design an example application solving that problem with the given requirements it tries to satisfy.
Requirements:
Model size: 1GB
Requests per second: 500
Model response time: ~1sec/item
Unevenly distributed load throughout the day
Analysing the requirements
Based on the number of requests per second and the model’s response time we can conclude that a single model instance won’t be enough to handle the load, so we will need more resources to satisfy the load requirements.
A good idea is to have a pool of workers that handle the upcoming requests.
This pool can be provisioned in many ways including
- Raw EC2 instances
- Kubernetes
- AWS Lambda
- EKS
- ECS
and many more.
AWS Lambda
Considering the size of the model it’s pretty clear that any option including loading the model periodically is not feasible, as it will drown the application due to the slow i/o operation reading from the filesystem.
This means that AWS Lambda is not a good fit for the use case. If the model was much smaller Lambda would be a good option for this.
Though Lambda will load the model and then stay alive for around 15 mins I still consider this too short and leading to too many unnecessary i/o operations.
* Workarounds are possible [see Lambda container reuse], but I feel this is too complicated and won’t consider it unless I have a strong reason to do so.
Kubernetes / Elastic Kubernetes Service
We can provision a cluster with many nodes to serve as a worker pool by manually installing Kubernetes on an ec2 instance, or - if we don’t feel like shooting ourselves in the foot, we can use EKS and skip the manual Kubernetes configuration.
While this is a great solution, it requires a solid team and lots of dev-ops and engineering expertise to keep alive - cluster updates, provisioning, security, and networking are just the bare minimum to set up such an application on that infrastructure.
Definitely, the flexibility here is nearly unlimited, and it’s a bit more platform-agnostic compared to other solutions as Kubernetes is a standardized open-source technology but assuming we are working on a new service building a proof of concept I wouldn’t invest the time at this stage until I have a deeper understanding of my application and its scope.
In terms of architecture complexity, this solution is simpler as it does not require an external Load Balancer, since the Kubernetes built-in Ingress can do a pretty good job balancing the load without paying for a dedicated Load Balancer in AWS.
Elastic Container Service
Since we have our application containerized, we can utilize the AWS Elastic Container Service, which is similar to K8S and EKS, but uses proprietary AWS control plane and is way easier to configure and manage than EKS.
We can create a cluster of EC2 instances hosting our containers, or we can go a step further and use Fargate which is a serverless engine allowing building apps without managing servers.
Bottom line ECS is an out-of-box solution for managing our cluster of workers, and Fargate is a solution managing the infrastructure for the workers themselves, which essentially leaves us with the only burden of managing our worker application itself.
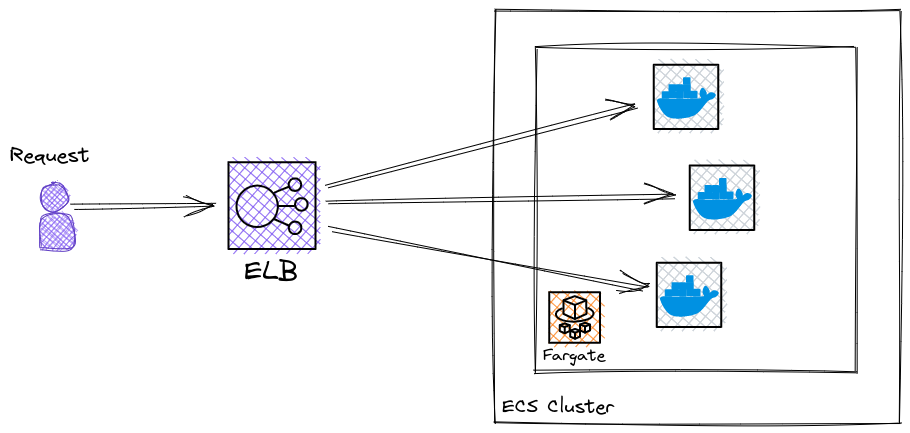
Elastic Load Balancer
After having the cluster set up, we need a load-balancer to distribute the traffic among the container instances.
We have two options worth exploring:
Application Load Balancer
Working at level 7 (HTTP), ALB provides great flexibility in choosing how to distribute the load of your application. If there is a custom field you want to consider when distributing the load, or you want to ensure certain properties are met (e.g. reading your own writes ) ALB is going to be your choice.
Network Load Balancer
Given the requirements of our application, we are completely okay with not implementing any custom logic affecting the balancing of the load, so we can use NLB, which works on level 4 of the OSI model, allowing it to achieve great performance and scale to millions of requests per second.
With that, the design of our scalable application serving the heavy ML model is done.
Reviewing the requirements, we can conclude the following:
- The container can load the 1 GB and store it in memory for a long time
- The Network Load Balancer and Fargate can easily handle the 500/sec requests
- Fargate will scale up and down to the required number of containers to process all the requests in parallel and adapt to the load level
Further optimizations:
We can further optimize the application to both reduce cost and resources and increase efficiency.
Some on top of the head ideas that help achieve that:
- Group items to utilize batch predictions Buffering items in a queue and processing them in a batch of 100 will almost not affect the response time due to the number of requests per day, while a Machine Learning model can significantly benefit from such batching utilizing vectorized computations.
- Utilize a GPU inside the docker container Docker allows using a GPU if such is available. EC2 has GPU Instances available, which can reduce the 1 second response time of the model to a couple of milliseconds.
Thank you for reading!